Abstract
The Location Routing Problem (LRP) has extensive applications in emergency medical facility selection. It involves a complex spatial optimization problem of selecting the optimal facility locations from a set of demand points and candidate facility locations and planning the most efficient routes. This study introduces a two-stage solution approach based on deep reinforcement learning, which fully leverages the potential of deep reinforcement learning in handling sequential decision problems. Firstly, in the location selection stage, through the interaction between an agent and the environment, the agent needs to choose facility locations from numerous demand points to either maximize overall profit or minimize overall costs. This stage determines central points and allocates demand points to the nearest facility locations. Subsequently, in the route planning stage, the agent decides how to distribute deliveries among the pre-selected facility locations to minimize overall route length or costs. Experimental results demonstrate the effectiveness of this method in addressing location routing problems. It may provide valuable support for responding to emergencies and disaster events, helping decision-makers make more intelligent choices for facility locations and route planning, ultimately enhancing service response speed and efficiency. Furthermore, this method holds broad application potential in other domains, further advancing the development and utilization of deep reinforcement learning in spatial optimization problems.
Location Routing Problem
LRP jointly considers the facility location problem (FLP) and the vehicle routing problem (VRP). Watson-Gandy and Dohrn, Salhi, S., & Rand, G. K. have proven that the strategy for solving LRP by dismantling LRP into FLP and VRP and solving those problems sequentially is not optimal. Therefore, constructing the solving strategy that could consider FLP and VRP as a unity and solve them simultaneously to find the optimal solution is critical in processing LRP. Currently, the exact and heuristic algorithms are mainly applied to solve LRP.
LRP is a traditional strategic-tactical-operational problem that considers a set of potential facilities and a set of customers. The main decisions of LRP are:
• The number and location of facilities to open,
• the allocation of customers to the opened facilities,
• The design of routes to serve customers of each facility using a fleet of vehicles.
As with most other models, one cannot capture all aspects of a real-life LRP with one mathematical model. Considering the complex real-life scenarios, LRP has a lot of variant problems with different objectives and constraints. Therefore, identifying the constraints of each sub-problem, such as facility location, allocation, and routing problem, is essential for solving LRP.
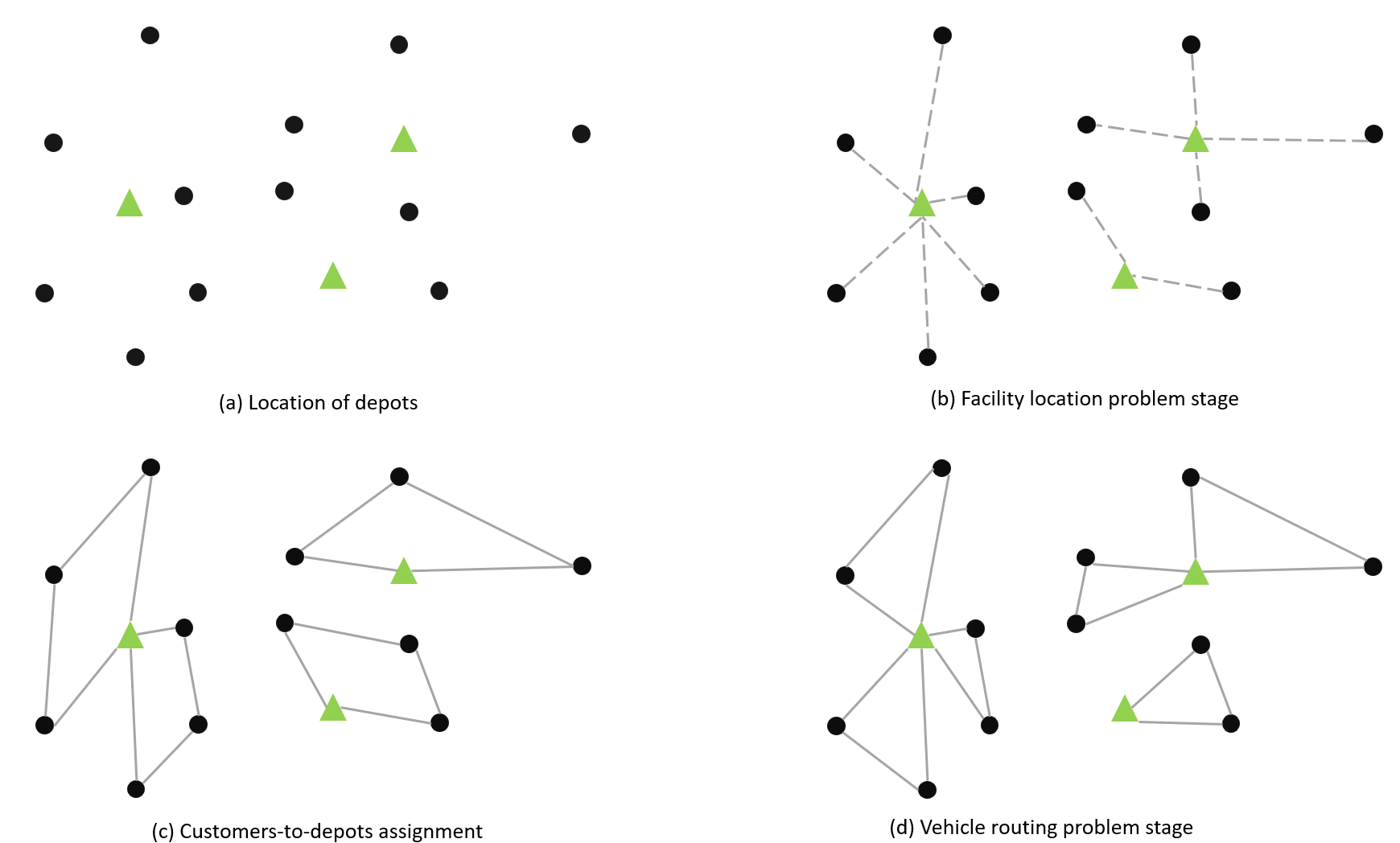
Figure 1: An illustrative example of LRP
Methodology
In the Location Routing Problems (LRPs), there are two main problems to address: location problem and route planning. Both of these problems can be modeled as sequential decision processes. In this section, we propose a two-stage algorithm based on deep reinforcement learning (DRL) to solve LRP, comprising the location problem stage and the route planning stage. In the location problem and routing problem, there are three types of nodes: demand points, logistics centers, and distribution centers.
(1)Location Problem Stage
In the location selection stage, we model the problem as a Markov Decision Process (MDP). The intelligent agent needs to choose one or more locations from all demand points to construct facilities, aiming to maximize overall revenue or minimize overall costs. To achieve this, we follow these steps:
• State: Define a state representation that includes the current chosen facility locations, the status of demand points, and other relevant information.
• Action: Define an action space in which the agent can choose the locations for constructing facilities.
• Reward: Design a reward function so that the agent can receive appropriate reward signals based on the chosen locations. Rewards can consider factors such as costs, revenues, and the degree of demand fulfillment.
Once this stage is completed, the facilities' deployment locations are determined, and these points are considered as central points, with each demand point assigned to the nearest facility point.
(2)Route Planning Stage
In the route planning stage, the routing problem can also be modeled as a Markov Decision Process. In this stage, the intelligent agent needs to decide how to allocate deliveries between the selected facility locations to minimize the overall path length or costs.
The two-stage algorithm's solution framework is illustrated as follows:
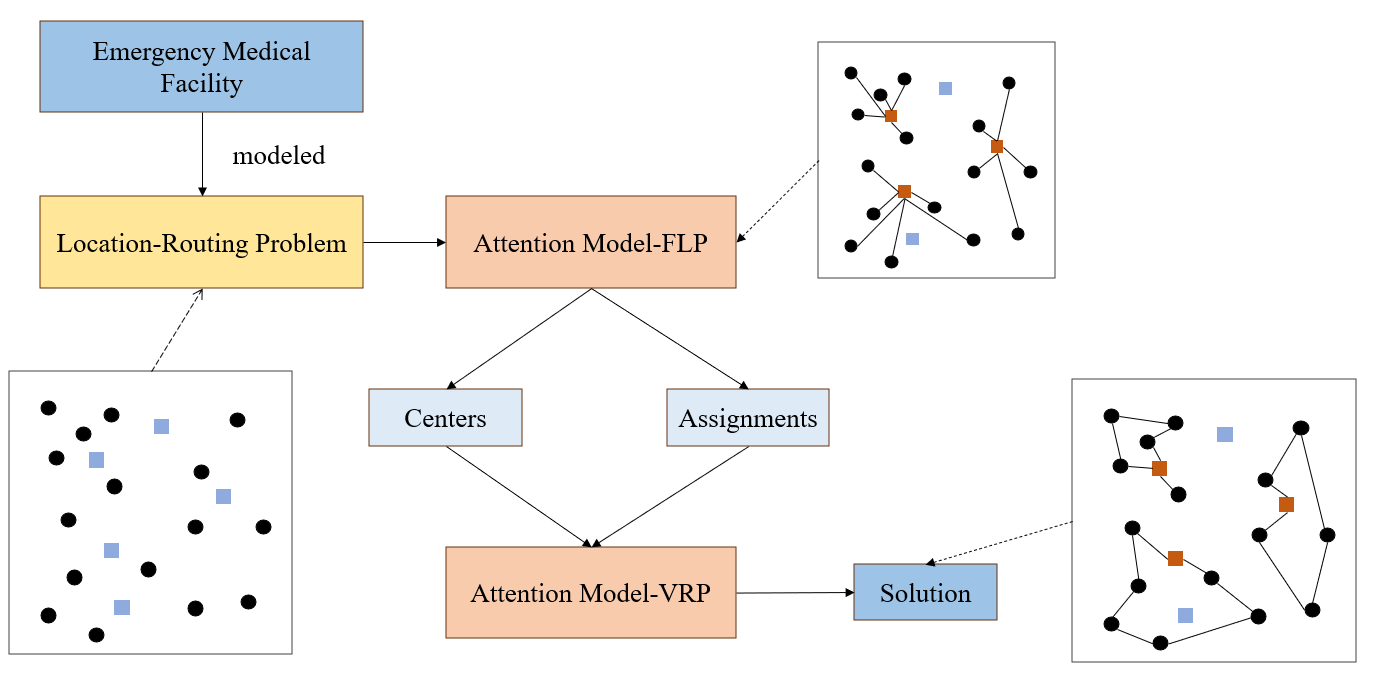
Figure 2: The structure of the two-stage algorithm for solving emergency medical facility location problem.
(3)Deep Reinforcement Learning Algorithm
We are using the REINFORCE algorithm to train our Attention Model- Facility Location Problem (AM-FLP) and Attention Model - Vehicle Routing Problem (AM-VRP). This algorithm is a type of policy gradient method. The algorithm steps are as follows:
• Define Policy Functions π(a|s): Define a policy function π(a|s) that describes the probability distribution of taking action a given a state s. We use π_FLP (a|s) and π_VRP (a|s) to represent the policy functions for the AM-FLP and AM-VRP, respectively.
• Sample Trajectories: For each trajectory, calculate the cumulative return. The return reflects the quality of executing the policy during a single attempt.
• Compute Returns: For each trajectory, compute the cumulative return. The return represents the quality of executing the policy in a single attempt.
• Update Policy: Based on the computed gradient information, employ gradient descent to update the parameters of the policy function, with the goal of increasing the expected return.
• Repeat Training: Continuously repeat the above steps until the policy function converges to a satisfactory policy or reaches a predefined number of training iterations.
Experiments and Analysis
Deep reinforcement learning, through continuous interaction between an agent and its environment to maximize rewards, is effective in handling sequential decision problems. We propose a new approach to the two-stage location routing problem (LRP) based on deep reinforcement learning. In this section, we first discuss how to utilize deep reinforcement learning to solve LRP, then implement problem-solving using this framework, and finally conduct generalization experiments.
For the LRP, we constructed two different attention model, AM-FLP and AM-VRP, for solving location problem and routing problem, respectively. We randomly generated 2000 instances for evaluating results. Each example consists of 50 demand points, and the task is to select 8 points out of the 50 demand points as central points. Then, following a greedy approach, the remaining demand points are assigned to the nearest central points, resulting in the classification of all nodes into 8 categories. Finally, for each category, the shortest path is chosen to traverse all the nodes. The experimental results are shown in Table 1. N represents the number of the demand points and p presents the number of the centers.
Table 1 The comparison results of Gurobi vs. GA vs. AM for location routing problem on N=50, p=8
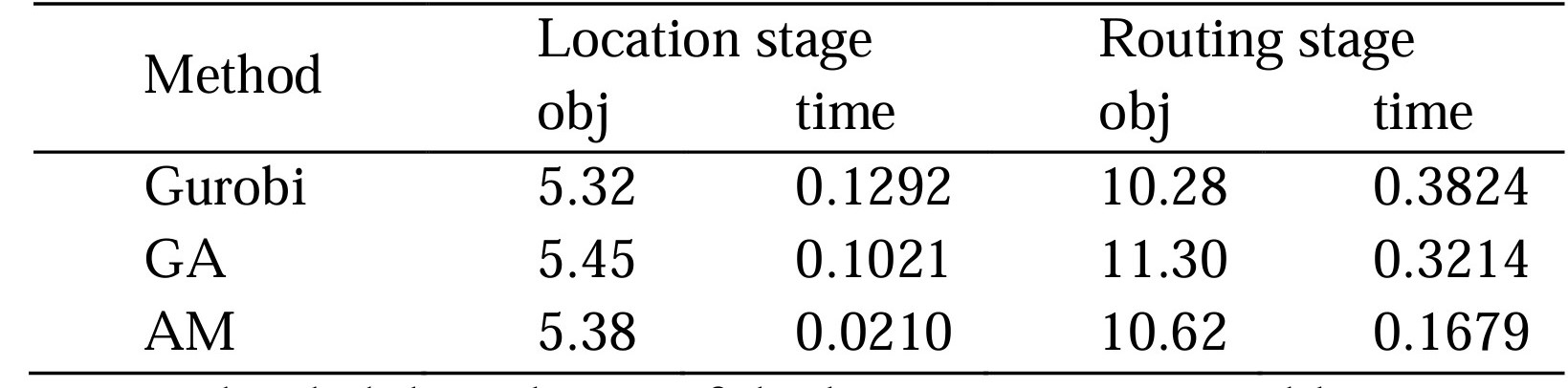
We divided the solution of the location-routing problem into two stages. Table 1 illustrates three different methods in terms of their objective functions and solution times in the location selection stage and the path planning stage. Gurobi, being recognized as the best solver, performs exceptionally well in this problem. It consistently obtains optimal solutions quickly, even in instances with 50 nodes. On the other hand, Genetic Algorithm (GA) is a heuristic algorithm, and its results are relatively less favorable compared to the other two algorithms. The gap between its objective values and the optimal solutions is the widest, which may be attributed to the parameter settings within the genetic algorithm. Our proposed method, which employs deep reinforcement learning (AM), exhibits a smaller gap from the optimal solutions compared to GA. Furthermore, it boasts the shortest solution times among the three methods. This suggests that our proposed approach achieves a balance between solution time and accuracy to some extent, making it a highly promising method. Overall, the results demonstrate that our proposed approach has the potential to be a valuable contribution in addressing the trade-off between solution time and precision in the context of the location-routing problem. More details of the code is available at:https://github.com/HIGISX/hispot.
Conclusion and Future Works
The location routing problem holds significant importance in practical production. It directly impacts resource allocation, logistics efficiency, and service quality for businesses, making it crucial for their operations and competitiveness. This study has introduced an innovative solution—a two-stage approach based on deep reinforcement learning—to address the location routing problem, with a specific focus on emergency medical facility selection. This method leverages the full potential of deep reinforcement learning in tackling sequential decision problems. Through the interaction between the agent and the environment, it effectively optimizes the selection of emergency medical facility locations and route planning, enhancing overall efficiency and quality. This research provides a new and efficient approach for the selection of emergency medical facilities, holding significant promise for practical applications and offering robust support and decision-making tools for addressing emergencies and disasters. Future studies could further explore the method's generalization capabilities and its potential applications in other domains, thereby extending its practical value.